En el presente documento se describe la configuracion de Humio en los clusters de AKS de Produccion ( prod) para que envien su log a dicha plataforma.
1. CONTROL DE VERSIONES DEL DOCUMENTO
| Autor | Javier Caparo |
| Version | 1.0 |
| Fecha | 10/01/2022 |
2. Service Mesh - K8s - Comparativa
Que es Service Mesh en K8s?
-
En términos generales, un service mesh puede ser considerado como una infraestructura de software dedicada para manejar la comunicación entre microservicios. Service Mesh Architecture
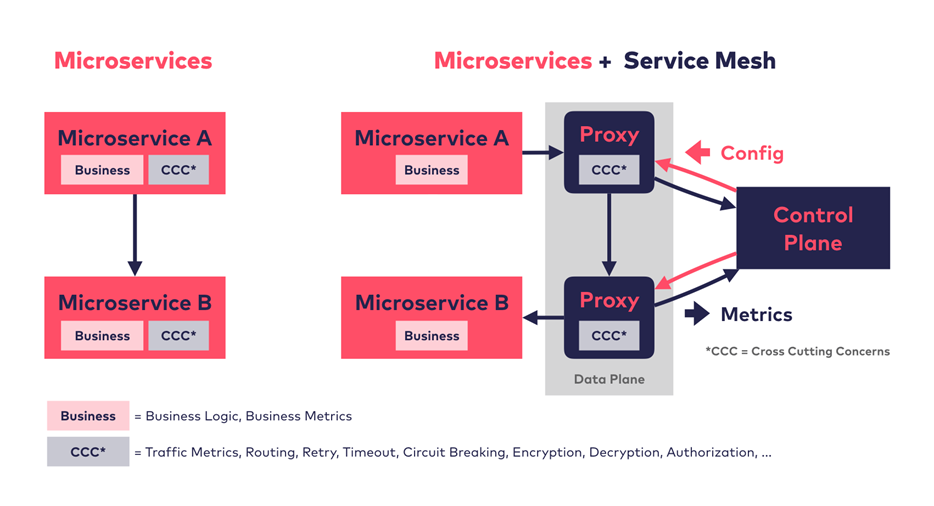
Sin Service Mesh, ... cada microservicio implemneta su propia logica de negocio y el llamdao cross cutting concerns (CCC) x si mismo..
Con Service Mesh ... las funciones de CCC como metricas de trafico, routing, encryptamiento se mueven fura del microservicio hacia su proxy. La lógica del negocio queda en el microservicio. Peticiones de entrada y salida ( requests) son ruteadas transparentemente x el proxy de cada servicio. Adicionalmente a esta capa de proxies (data plane), un service mesh implementa una capa control ( control plane) . la cual distribuye actualizaciones a todos los proxies y recibe métricas que se colectan de todos los proxies para procesamientos posteriores, tal como monitoreo utilizando Prometheus.
Porque es necesario?
- Cuando disponemos de una aplicación distribuida (ya sea pública o privada), basada en una arquitectura compuesta por microservicios, contenedores y una capa de orquestación (por ejemplo Openshift o Kubernetes); y en la que se encuentran cientos de microservicios e instancias de estos que se levantan y eliminan en base a necesidades puntuales de escalado, el camino que sigue una sola solicitud a través de la topología del servicio puede ser increíblemente complejo. Esta combinación de complejidad y criticidad motiva la necesidad de introducir una capa dedicada para la comunicación entre servicios, desacoplada del código de aplicación y capaz de capturar la naturaleza altamente dinámica del entorno subyacente, dotándolo a su vez de herramientas que permitan monitorizar, gestionar y controlar estas comunicaciones.
¿De qué está formado?
- Para poder llevar a cabo toda la funcionalidad que debe aportar un service mesh, éste se basa en implementar algunos de los patrones de diseño y de aplicaciones distribuidas ya conocidos, pero en lugar de aplicarlos sobre el código (como venía siendo frecuente), lo realiza sobre la propia infraestructura.
- Pero antes de hablar de cada uno de los componentes que conforman un service mesh, haremos una introducción a uno de estos patrones de los que hace uso. Estamos hablando del patrón sidecar.
- En el patrón sidecar, la funcionalidad de un proceso (servicio) principal se extiende o mejora mediante un proceso “paralelo” sin apenas acoplamiento entre ambos.
- El comportamiento es similar al de un proxy que proporciona al proceso principal todos los servicios “commodity” de infraestructura que necesita (por ejemplo, descubrimiento de servicios, circuit breaker, etc.).
- Este patrón es particularmente útil cuando se utiliza Kubernetes como plataforma de orquestación de contenedores. En Kubernetes se utilizan los “pods”, cada uno de los cuales está compuesto por uno o más contenedores de aplicaciones.
- Por tanto, un sidecar es un contenedor de “utilidad” en el pod y su propósito es dar soporte al contenedor principal. Es importante tener en cuenta que el sidecar por si sólo no sirve para nada, sino que debe combinarse con uno o más contenedores principales.
- En general, el contenedor sidecar es reutilizable y puede combinarse con numerosos tipos de contenedores principales.
- Plano de Datos (Data Plane)
- Imaginemos un conjunto de servicios independientes en el que cada uno de ellos está desplegado junto con un proxy-sidecar en un mismo pod de Kubernetes.
- Hagamos, además, que cada servicio se comunique únicamente con su propio proxy-sidecar y que, en lugar de comunicarse directamente entre ellos, sean éstos últimos (los sidecars) los que terminen siendo los responsables de la entrega fiable de las peticiones a través de una topología o arquitectura que puede ser todo lo compleja que necesitemos.
- Podemos ver que cada servicio solo se comunica sólo con su propio proxy-sidecar.
- Llevemos nuestra imaginación un paso más allá y, mentalmente, eliminemos del esquema los propios servicios de negocio, dejando simplemente el conjunto de sidecars y la forma de intercomunicación entre ellos.
- Ahora podemos ver con más claridad, cómo el diagrama resultante representa la “malla de conectividad” subyacente:
- Si se eliminan los servicios de negocio, la propia topología de conectividad se hace patente.
- Bien, pues a este conjunto de servicios y proxy-sidecars (en definitiva, a esta malla) se le asigna el nombre de Data Plane o “Plano de datos”.
- A un alto nivel, la responsabilidad del "plano de datos" es asegurar que las solicitudes sean entregadas desde el microservicio A al microservicio B de una manera confiable, segura y oportuna, siendo el encargado de proporcionar las siguientes funcionalidades: • Descubrimiento de servicios (Service Discovery). • Comprobación de disponibilidad (Health check). Ya sean tanto comprobaciones activas como pasivas. • Enrutamiento y balanceo de carga: time-out, reintentos, circuit-breaker, fail-over… • Securización y control de acceso (autenticación / autorización). Securización del canal de comunicación con TLS, ACLs… • Observabilidad: Métricas, monitorización, logging y trazabilidad distribuidos… Plano de Control (Control Plane) Por otro lado, tendríamos la última pieza que forma parte de la solución, la cual recibe el nombre Control Plane o Plano de Control. Este elemento será el encargado de gestionar y monitorizar todos las instancias de sidecars, siendo el punto ideal para implementar políticas de control, recolección de métricas, monitorización... Es una pieza obligatoria para el correcto funcionamiento de un service mesh. Pero esta pieza no tiene porque ser un elemento que presente una interfaz de usuario (Gráfica, CLI...), sino que podría ser incluso el propio administrador el encargado de actuar como Plano de Control y realizar la configuración de los sidecar y otros parámetros de configuración de la plataforma (aunque como parece obvio, no es lo deseable). Podemos ver la conjunción entre plano de datos y plano de control. Otro punto importante es que un service mesh puede funcionar a nivel de capa de aplicación, no sólo de red. Esto hace que pueda tener la capacidad de obtener información más detallada sobre las peticiones, como por ejemplo, poder distinguir entre peticiones que finalizan con un error 500 o un 404 (lo cual no es posible a nivel de capa de red). De este modo se puede hacer uso de esta información para diferentes ámbitos (trazabilidad, health checking…). A pesar de que las funcionalidades mencionadas anteriormente, se proporcionan dentro del plano de datos mediante los proxy-sidecar. La configuración global de estas funcionalidades se realiza dentro del plano de control. Es el plano de control quien toma todos los proxy-sidecar sin estado y los convierte en un sistema distribuido. Si en este momento volvemos a la analogía con la pila TCP/IP, podemos decir que el plano de control es similar a la configuración de los switches y routers para que TCP/IP funcione correctamente por encima de éstos. En un service mesh, el plano de control es por tanto, el responsable de configurar la red de proxy-sidecar. Las funcionalidades del plano de control incluyen la configuración: • Enrutamiento. • Balanceo de carga. • Circuit-breaker, políticas de reintentos, time-outs… • Despliegues. • Descubrimiento de servicios.
En resumen:
• Plano de datos: toca cada paquete/petición del sistema. Responsable del descubrimiento de servicios, health check, enrutamiento, balanceo de carga, securización y observabilidad. • Plano de control: proporciona la política y la configuración para todos los planos de datos existentes en el service mesh. No toca ningún paquete/petición en el sistema. El plano de control convierte todos los planos de datos en un sistema distribuido. Patrones de despliegue Podríamos establecer dos posibles patrones de despliegue para un service mesh: • Patrón de despliegue basado en un proxy por host. • Patrón de despliegue basado en proxies-sidecar.
* Patrón de despliegue basado en un proxy por host
- En este tipo de despliegue, un proxy es desplegado por cada host, siendo este una máquina virtual o host físico o un nodo worker de Kubernetes.
- En esta tipología, múltiples instancias de servicios de aplicación se ejecutan en un mismo host y todos ellos enrutan el tráfico a través de una misma instancia de proxy.
- En el caso de Kubernetes, la instancia de proxy puede ser desplegada como un daemonset.
- En este tipo de despliegue, los servicios A, B, C se comunican con los otros a través de su correspondiente instancia de proxy. En cada hosts, corren múltiples instancias de A, B, C.
*Patrón de despliegue de proxy sidecar
- En este patrón, un proxy sidecar es desplegado por cada instancia de cada servicio. Este modelo es muy útil para despliegues que utilizan contenedores o Kubernetes.
- En este último caso, el contenedor del sidecar-proxy puede ser desplegado junto con el contenedor del servicio de aplicación como parte de un pod de Kubernetes.
- Obviamente, este tipo de despliegue requiere más instancias del sidecar, por lo tanto, un perfil de recursos más pequeño para sidecar suele ser lo apropiado.
- Si el perfil de recursos es un problema, se puede desplegar la instancia de service mesh como un daemoset, lo que reducirá el número de contenedores de service mesh a uno por host en lugar de uno por pod.
- En este tipo de despliegue, los servicios A, B, C se comunican entre sí a través de su propia instancia de proxy sidecar.
- Enrutamiento dinámico de peticiones
- En una implementación de service mesh, el enrutamiento dinámico de peticiones permite encaminar una petición a una versión específica del servicio (v1, v2, v3) en el entorno concreto (dev, stag, prod) a partir de reglas de enrutamiento.
- La implementación real de este tipo de reglas de enrutamiento dinámico podría variar entre diferentes frameworks de service mesh.
- Aún así, la mecánica básica sigue siendo la misma: un servicio origen realiza una petición a un servicio destino; la versión exacta del servicio destino es determinada por el service mesh en base a las reglas de enrutamiento establecidas.
- Este tipo de enrutamiento dinámico también ayuda con la conmutación de tráfico en escenarios de despliegue comunes como los despliegues Azul-Verde, despliegues Canario, pruebas A/B, etc.
- En este caso, el service mesh determina la versión de servicio destino de forma dinámica según las reglas de enrutamiento. A continuación, controla el porcentaje de solicitudes enrutadas a dos versiones diferentes del servicio de destino, lo que permite desplazar el tráfico de forma incremental y controlada.
- Implementaciones de Services Mesh
- Existen diferentes tipos de soluciones de service mesh actualmente, como puede ser Nelson, que utiliza Envoy como su proxy-sidecar y construye un plano de control robusto haciendo uso del stack de Hashicorp (por ejemplo: Nomad, Consul, Vault…).
- También Smartstack, el cual crea un plano de control alrededor de HAProxy o NGINX y otros elementos como Nerve, Synapse o Zookeeper, demostrando además que es posible desacoplar el plano de control y el plano de datos.
- Por otro lado, están Linkerd e Istio que son dos de las implementaciones open source de service mesh más populares actualmente. Ambas siguen una arquitectura similar, pero diferentes mecanismos de implementación.
- No obstante, no hay que perder de vista a Conduit (aún experimental), el cual es un service mesh ultraligero para Kubernetes de los mismos que han implementado Linkerd.
Istio vs Linkerd
Dado que Istio y Linkerd son dos de las más populares implementaciones de service mesh, en la actualidad, vamos a realizar una pequeña comparativa:
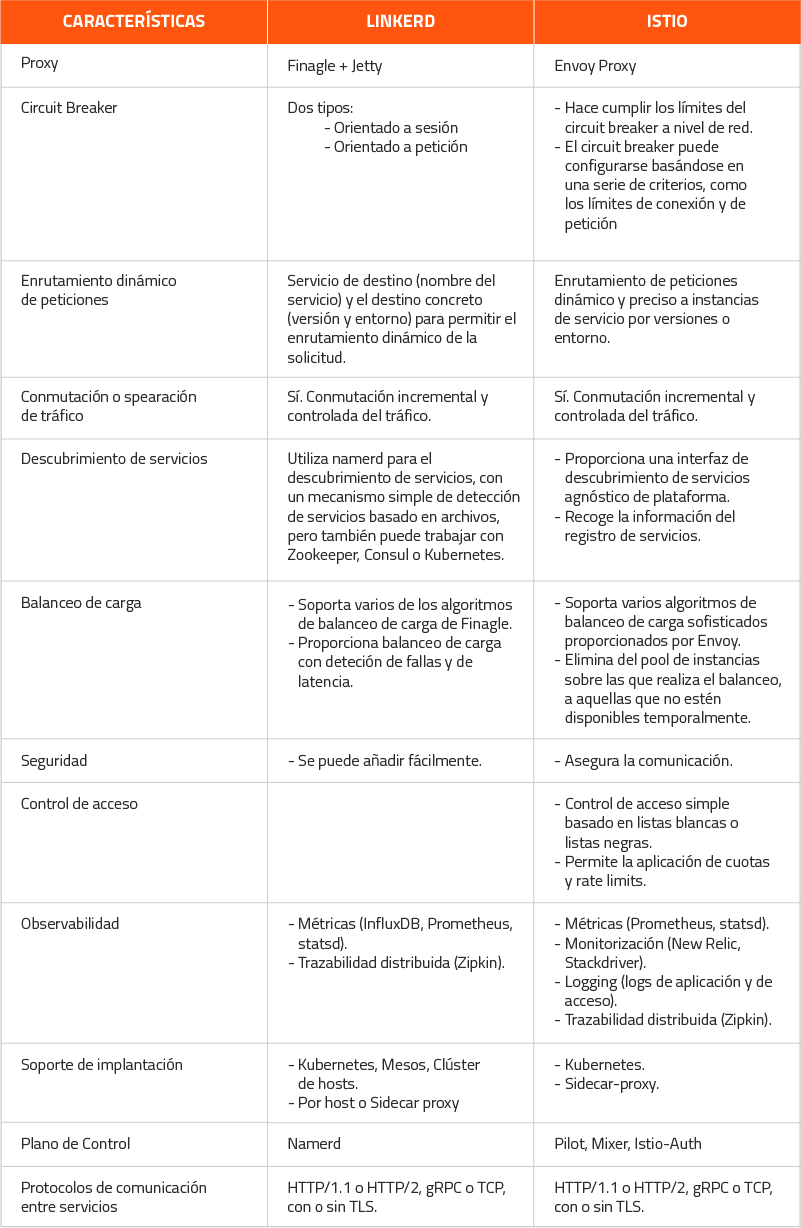
¿Cuándo se debe utilizar?
- En una solución de arquitectura en la que confluyen microservicios, contenedores y una capa de orquestación (por ejemplo Kubernetes u Openshift) siempre sería muy recomendable incluir las funcionalidades aportadas por un service mesh para gestionar las comunicaciones entre microservicios.
- La obligación de este uso se hace más patente aún si los microservicios, tal y como ocurre en este tipo de arquitecturas, son políglotas. Es decir, estarán implementados con diferentes frameworks y/o lenguajes de programación.
- También es recomendable valorar la posibilidad de incluir un service mesh cuando, aún teniendo una arquitectura de microservicios, ésta no se encuentra desplegada sobre una plataforma de orquestación (por ejemplo, Kubernetes), sino que en este caso varios microservicios se agrupan para ejecutarse sobre una o varias máquinas (física o virtual), que no son gestionadas de un manera centralizada.
- En este caso, se puede optar por un modelo de despliegue de service mesh que siga un patrón de un proxy por host.
- No obstante, en soluciones en las que el número de microservicios sea relativamente pequeño, y si todos ellos estuviesen implementados con un mismo framework (por ejemplo Spring Cloud) que proporcione los mecanismos con los que hacer frente a las necesidades de comunicación entre servicios ya mencionadas, podría no tenerse en cuenta el uso de una capa de Service Mesh.
- En este caso hay que ser consciente que deberán ser los desarrolladores quienes tengan que asumir la responsabilidad de incluir estas funcionalidades en los propios servicios, ya sea de manera manual o haciendo uso de librerías y/o componentes de terceros.
- Por poner un ejemplo concreto, en una arquitectura de microservicios con Spring Cloud, para proporcionar la funcionalidad de descubrimiento de servicios, no sería necesario incluir las dependencias con el cliente de Eureka.
- Tampoco lo sería el disponer del propio servidor Eureka, y esto mismo ocurriría con otras de funcionalidades aportadas por Spring Cloud, como Ribbon, Zuul...
Conclusión
- Un service mesh aborda algunos de los desafíos clave en lo que respecta a la realización de la arquitectura de microservicio. Pero como en muchos otros casos, el uso de un nuevo tipo de solución plantea una serie de pros y contras, los cuales siempre hay que tener muy en cuenta a la hora de abordarlos:
PROS
- Las funciones de red básicas se implementan fuera del código de microservicio y éstas son reutilizables. Descubrimiento de servicios, gestión de fallos...
- Resuelve la mayoría de los problemas de la arquitectura de microservicios en los que se solían tener soluciones ad-hoc: trazabilidad y logging distribuido, seguridad, control de accesos, etc.
- Proporciona más libertad cuando se trata de seleccionar un lenguaje de implementación de microservicios. No tiene que preocuparse por si un lenguaje determinado tiene o admite librerías para construir funciones de aplicación de red.
- Aporta mecanismos de enrutamiento inteligente. Pueden ser muy útiles a la hora de incorporar nuevas estrategias de despliegue de servicios (implantación progresiva de una nueva versión, despliegues Blue/Green o Canary), y/o para realización de testing (por ejemplo test A/B)...
* Contras
- Aumento de la complejidad. Teniendo un service mesh se incrementa drásticamente el número de instancias en ejecución que existen en una implementación de microservicios dada.
- Incremento de los puntos de fallo potenciales, derivados de la necesidad de tener otros componentes en ejecución. Al igual que ocurre con los ya existentes (microservicios), pueden tener problemas puntuales de indisponibilidad, pero con el agravante de que estos fallos pueden afectar al funcionamiento de toda la malla o a partes de ella. Hay, por tanto, que elegir muy bien la topología de nuestra malla de servios y asegurar la resiliencia de la misma
- Incremento de latencia por la agregación de saltos adicionales entre servicios (los realizados a través de los proxy sidecar del service mesh).
- Inmadurez. Las tecnologías de service mesh son relativamente nuevas para declararse como una solución completa.
- También hay que dejar claro que este tipo de planteamiento viene a dar solución a problemas comunes de comunicación entre servicios.
- Pero no son el mecanismo para solventar otro tipo de problemas como el enrutamiento complejo de peticiones, la transformación o mapeo de tipos, o la integración con otros servicios y sistemas, los cuales deben resolverse en la lógica de negocios de un microservicio (por ejemplo mediante el uso de frameworks de integración como pudieran ser Conductor, Apache Camel o Spring Integration)
QUE Service MESH podriamos implementar en AD TdP?
- Realizaremos una PoC con Linkerd dado su facilidad para instalarla y su baja complejidad para conocerla a fin de verificar los beneficios en el despliegue de microservicios en los clusters AKS ( K8s) de las mesas.